
One of the numerous applications of Artificial Intuition is that of accelerating Machine Learning, a long and energy-intensive process, requiring expensive compuational hardware and large amounts of training data.
Machine learning (ML) is a field in artificial intelligence concerned with the development and study of statistical algorithms that can learn from data and generalise to unseen data, and thus perform tasks without explicit instructions. Statistics and mathematical optimisation methods comprise the foundations of machine learning.
Training Costs (Time & Memory)
Whether you’re doing supervised, unsupervised or reinforcement learning, the quality and quantity of data is key. The number of dimensions (features) in a dataset significantly impacts the computational cost of machine learning models:
- Curse of Dimensionality: As dimensions grow, the volume of the feature space increases exponentially, requiring more data to maintain density.
- Matrix Operations: Models like linear regression, SVMs, and neural networks involve matrix multiplications which scale with O(d²) or worse.
- Optimization: Gradient descent converges slower in high-dimensional spaces (more parameters to update).
Statistical Cost (Overfitting & Generalization)
Overfitting Risk: High dimensions increase model complexity, leading to overfitting if data is sparse.
Regularization Needed: Techniques like L1/L2 regularization (Ridge/Lasso) or dropout (in neural networks) become essential to constrain parameters.
Data Requirements: The “rule of thumb” suggests needing exponentially more samples to maintain generalization as dimensions grow.
Reduce Training Data Dimensionality
Complexity Profiling can eliminate variables that do not contribute information.
In the example below out of the 230 features, 120 carry almost 98% of the information content of the entire dataset.
The remaining 110 carry very little information and may be discarded from the training set.

Reduce Number of Training Vectors
Only data frames which carry sufficient information and structure can be used to extract training vectors. In the example below, the following dimensions may be discarded: 3, 23, 27, 28 and 29.
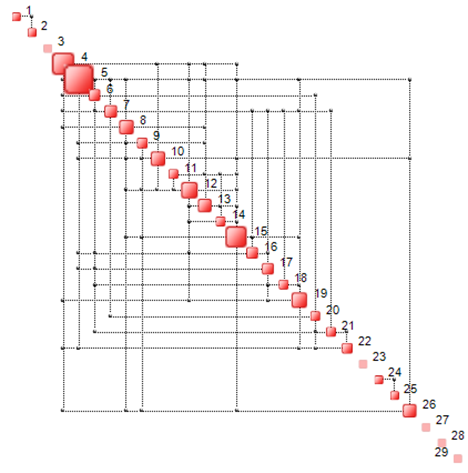
Low complexity training vectors can be discarded without significant loss of information.
Listen to podcast.

Pingback: Accelerating Machine Learning – An Update – Artificial Intuition