
As we know, Machine Learning, is a long and energy-intensive process, requiring expensive computational hardware and large amounts of training data. In a recent blog, we have shown how QCM-powered Artificial Intuition by Ontonix, is able to accelerate Machine Learning by eliminating dimensions, or entire training vectors, if their information content is negligible.
The above can be accomplished via a technique known as Complexity Profiling, a proprietary, non-linear algorithm, which produces an information content spectrum of an N x M data array.
This short blog illustrates an industrial example, relative to a sophisticated electro-mechanical system with 6292 degrees of freedom (features). Complexity Profiling has determined that only 1612 of the above are necessary to describe the system while conserving 98% of the information (complexity) contained in the entire data set.
The complete, aggregated Complexity Profile is illustrated below in the top bar chart. The bottom chart is simply the zoom of the significant part of the upper one. The height of each bar is proportional to the information content of each degree of freedom.
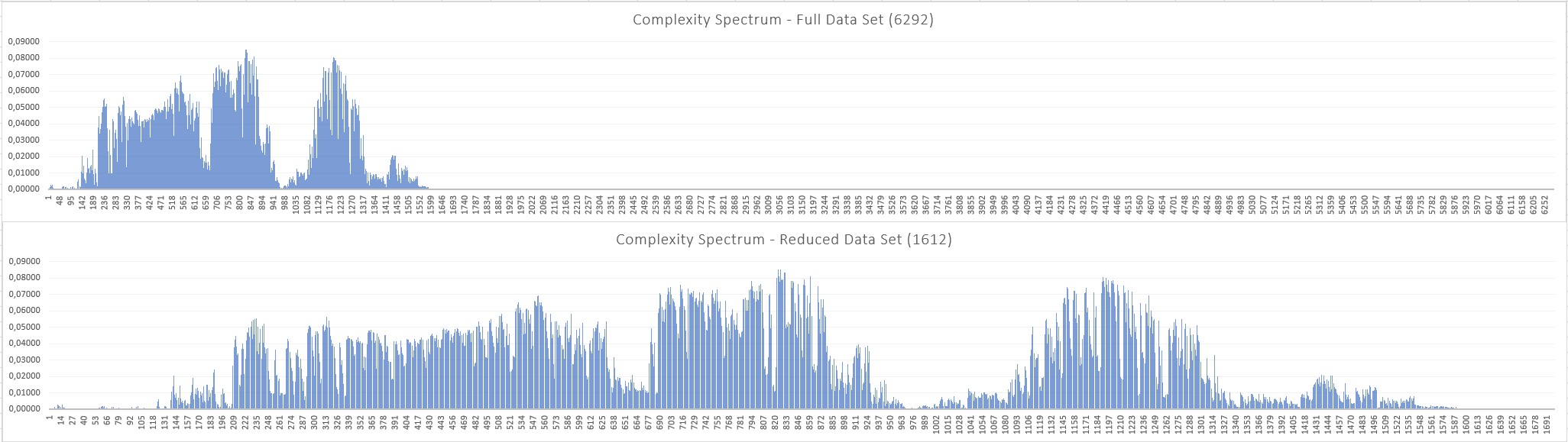
Tilting the charts, as shown below, allows to appreciate better the details.
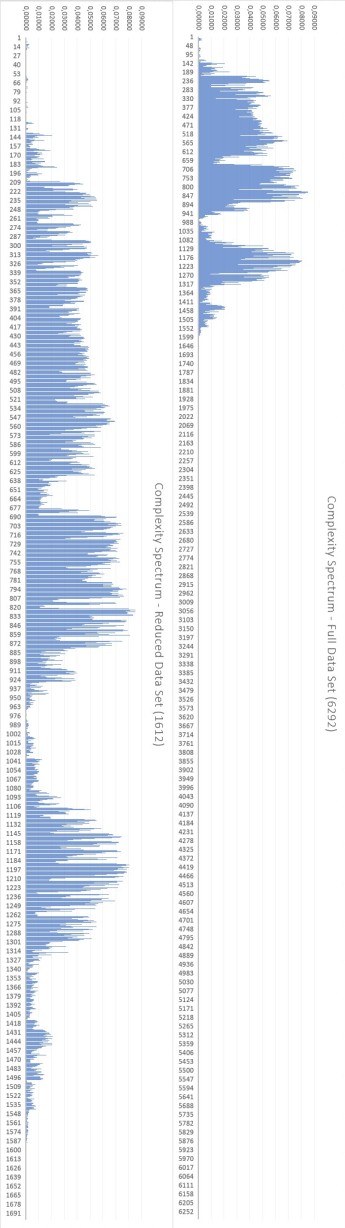
The bottom line is that this technique reduces the size of the training set by 74%, while maintaining 98% of the information content of the full data set. If one is willing to reduce this to 95%, the size of the data set is reduced even more dramatically. It is not difficult to imagine what the advantages may be. Doubling features may more than double training time (e.g., SVM scales up to O(d×n²)).
An additional benefit stems from knowing what counts and what doesn’t, but this doesn’t seem to be too important nowadays.
PS. This technique can be used to accelerate optimisation as well as the synthesis of Reduced Order Models for contol purposes.
Listen to podcast.

Contact us for information.

0 comments on “Accelerating Machine Learning – An Update”