
The human genome contains 20000-25000 genes (3 billion letters). The approximate number of atoms necessary to encode human DNA is 200 billion. For example, Thymine’s base is a pyrimidine ring compound and it contains 15 atoms. Its pentose sugar has 15 atoms also (the 5-carbon sugar used for ribonucleic acid (RNA) is very similar, but it has an extra oxygen atom). This leads to a total of 34 atoms for a thymine nucleotide.
DNA sequence has the objective of establishing the sequence of nucleotides. In 2000 the entire fruit fly DNA has been sequenced. In 2001 human DNA has been sequenced for the first time.
In principle, full genome sequencing can provide the raw nucleotide sequence of an individual organism’s DNA. However, further analysis must be performed to provide the biological or medical meaning of this sequence, such as how this knowledge can be used to help prevent disease. Methods for analysing sequencing data are being developed and refined. In May 2011, Illumina lowered its Full Genome Sequencing service to $5,000 per human genome.
An example of what a nucleotide sequence looks like is shown below (source: Wikipedia)
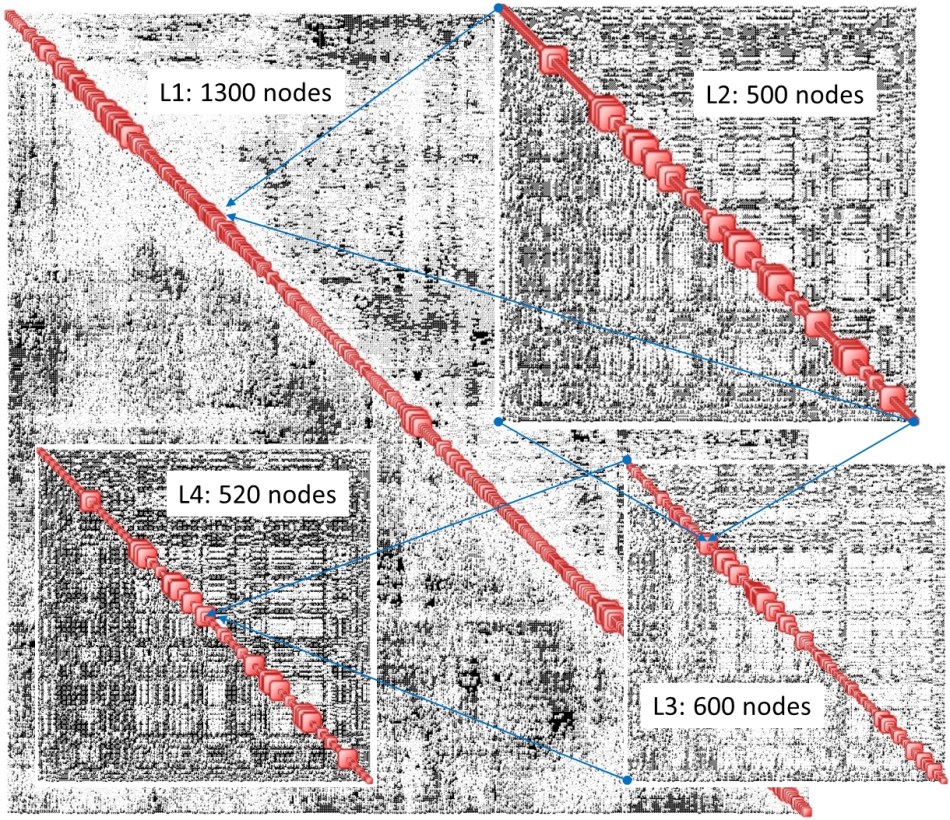
Ontonix is investigating the possibility of synthesizing the first Complexity Map of the human DNA. The idea is to identify functional relationships and pathways within the DNA. There are different ways of doing this. It all depends on the granularity of the description of the DAN itself. We can look, for example, at the 20000-25000 genes and try to identify how they interact and function as a system. This is the ‘coarse’ version. We can also look at the actual sequence – here we have 3 billion letters. And then we have a description at atomic level with over 200 billion atoms. So, we’re looking at a problem which, in its simplest form has a few hundred thousand variables. In the worst case we’re looking at 200 billion atoms – variables – which form an intricate 3D network. Just to give an idea of what a 200 billion variable looks like we have put together the scheme illustrated below – NB this is just a generic example. The L1 map contains 1300 blocks of nodes (sub-maps). Let us suppose that each of these 1300 blocks is made up of (L2) 500 blocks of nodes. Each of these is made up of 600 blocks (L3) and, finally each one of these is in turn made up of blocks of 520 nodes (L4). If you compute 1300 x 500 x 600 x 520 you get approximately 200 billion.
A Complexity Map offers a new representation of a system. It displays the structure of information flow within the system and indicates the hubs of this information traffic. This is very important if one wants to understand how a system really functions.
Today with 1 TB of RAM and our OntoNet QCM engine we can analyze systems having up to 1 million nodes (variables). Consider that an L1 + L2 description yields 1300 X 500 = 650000 variables. This means we can easily analyze even large proteins composed of hundreds of amino acids and hundreds of thousands of atoms. See here an example of Complexity Map of a protein.
To go to levels of granularity beyond L1 + L2 + L3 is not easy to achieve on ordinary computers. In the above example we’re looking at 390 000 000 variables. This is something we could potentially run on the Sunway system at the National Supercomputing Center in Wuxi, China. The Sunway system has the following characteristics:
| No. Cores: 10,649,600
Peak performance: 125000 Tflops/s LINPACK benchmark: 93 petaflops |
To go to the full L1 + L2 + L3 + L4 level of detail appears to be within the reach of current technology. In fact, on January 10-th, 2017, the largest Molecular Dynamics, with over 4 trillion particles has been run, read here. The simulation was run on 147456 cores. A Complexity Map of the human DNA can therefore be synthesized. We can therefore:
- Measure the complexity of the DNA. We know that it is complex, it is time to find out how complex that is
- Identify the genes that are the main drivers of DNA complexity
- Measure in cbits (complexity bits) how much information is encoded in the DNA
- Find out which genes are the hubs of the DNA
We are looking for partners – universities, research centers – to join forces with us. Contact us if interested.

0 comments on “The Complexity Map of the Human DNA. Is it possible?”