

Before you start to solve a problem (a numerical problem) you should check its conditioning. An ill-conditioned problem will produce very fragile and unreliable results – no matter how elegant and sophisticated solution you come up with it will be vulnerable. If decisions or strategies are based on fragile outcomes, those decisions and strategies will also be fragile. This means they will inevitably entail risk.
If someone provides you with a solution to a problem without specifying its numerical conditioning you should exercise caution.
Think of a simple and basic problem, a linear system of equations: y = A x + b. If A is ill-conditioned, the solution will be very sensitive to entries in both b and y and errors therein will be multiplied by the so-called condition number of A, i.e. k(A). That’s as far as simple linear algebra goes. However, most problems in life cannot be tackled via a linear matrix equation (or any other type of equations for that matter). This does not mean, though, that they cannot be ill-conditioned, quite the contrary.
Imagine that you have a set of data or simply a database. Suppose it is large and that it cannot be cast as a system of linear equations. How do you assess the “numerical conditioning of a database” or simply its quality? This is far from easy as it is practically impossible to assess the quality, precision, relevance or pedigree of all the entries of a very large database. However, something very interesting and useful can still be done.
First of all, one can determine of the data ‘contains’ structure, or rules, and patterns. Structure can be represented via Complexity Maps. Two examples – based on a database of 24 variables – are shown. The first is the case of sparse structure, i.e. a relatively small number of rules.
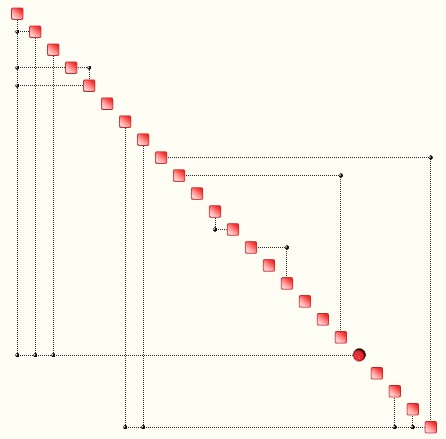
Most of the 24 variables are independent, i.e. are not related to any other variable. The second case shows the Complexity Map of another database of 24 variables, which is rich in structure and in rules.
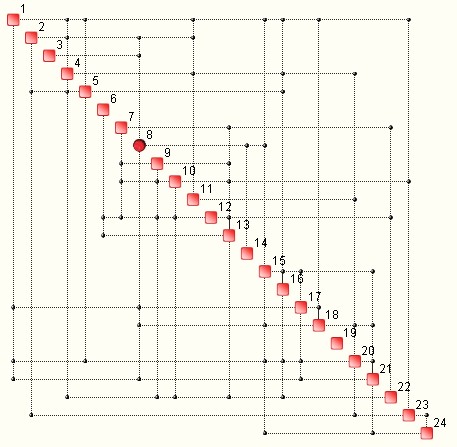
If a database has a very sparse Complexity Map, it means that much of the data contained therein is chaotic. This is equivalent to using chaotic data for making decisions and building strategies.
The importance of structure cannot be overstated. Knowledge, or a body of knowledge, is an organized and dynamic set of interdependent rules (hence structure). No structure no knowledge. A chaotic soup of numbers is just that.
A second issue is that of the robustness of the structure itself. If the structure of data is weak, even if it is rich, decisions based on that data will still be risky.
The robustness of data structures can be determined by computing the ratio of data complexity and its corresponding critical complexity. Again, two examples are shown below.


In other words, it is not sufficient to have structure in data (i.e. data that is not just chaos but data which contains some rules and patterns). The structure of the data in question must also be robust. This will clearly affect the robustness of one’s decisions.
The bottom line is: The ratio of data complexity and critical complexity is a good proxy of numerical conditioning (i.e. k(A)).
Any piece of data, if not accompanied by some sort of quality indication, is potentially meaningless. The greater the data set the more important this becomes.
Paradoxically, even though today we have devised highly efficient means of generating quickly huge amounts of data, quantitative approaches, such as the one described herein, are far from being popular. Why? Accountability. When you speak in terms of numbers you can be held accountable. Most people don’t like that.

Pingback: On Data Quality and Data-driven Business Models. – Artificial Intuition
Pingback: Processing Discrete, Uncorrelated Data – Artificial Intuition