
What are the main differences between Ontonix’s QCM/ Artificial Intuition approach to data analysis and early anomaly detection, and conventional methods such as statistics or Artificial Intelligence?
First of all, some facts about QCM/Artificial Intuition:
QCM/Artificial Intuition is a model-free approach. This means it does not require the synthesis of a mathematical representation (a surrogate, an emulation) of reality. In fact, the technique is data-centric.
In a real-time setting, QCM/Artificial Intuition works with raw data, even if the data changes in size (new data channels are added or removed on the fly) or if different portions of the data are sampled with different frequencies.
Since a model is not required, it is not necessary to build Reduced-Order Models. These are often necessary in order to cope with limited computational resources.
No assumptions as to the character of data are made. It is irrelevant if data is distributed normally, if it is continuous or discrete, or if it contains outliers or not. QCM/Artificial Intuition works with highly pathological data as well as with “text book” type of data. Some nasty examples are shown below.
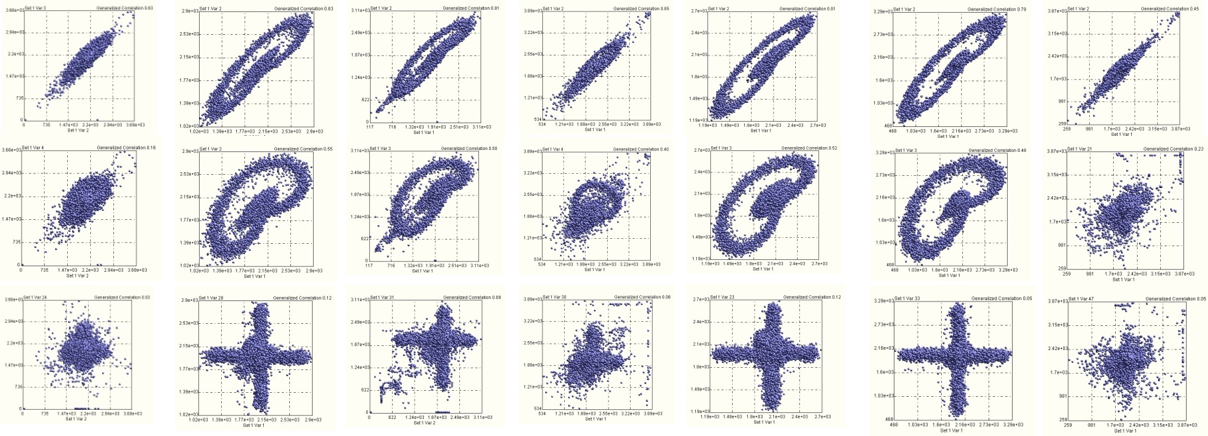
Building models on top of similar data may be quite a destructive process from the information content perspective.
The fact that a model is not needed is of paramount importance. First of all, a model must be validated. Models can be trusted only inside the domain in which they have been validated, not outside. When new factors come into play, a model must be updated and re-validated. This can be expensive. Finally, models are built based upon a-prioristic assumptions. These have to checked when a model is operated for any potential violations. None of this is of concern to QCM/Artificial Intuition.
The concept of correlation/covariance plays a central role in conventional data analysis and model building. This is, with all likelihood, the Achilles’ heel of data analysis. When things are nice and smooth, plain vanilla correlations work egregiously – see the top two rows in the figure below.
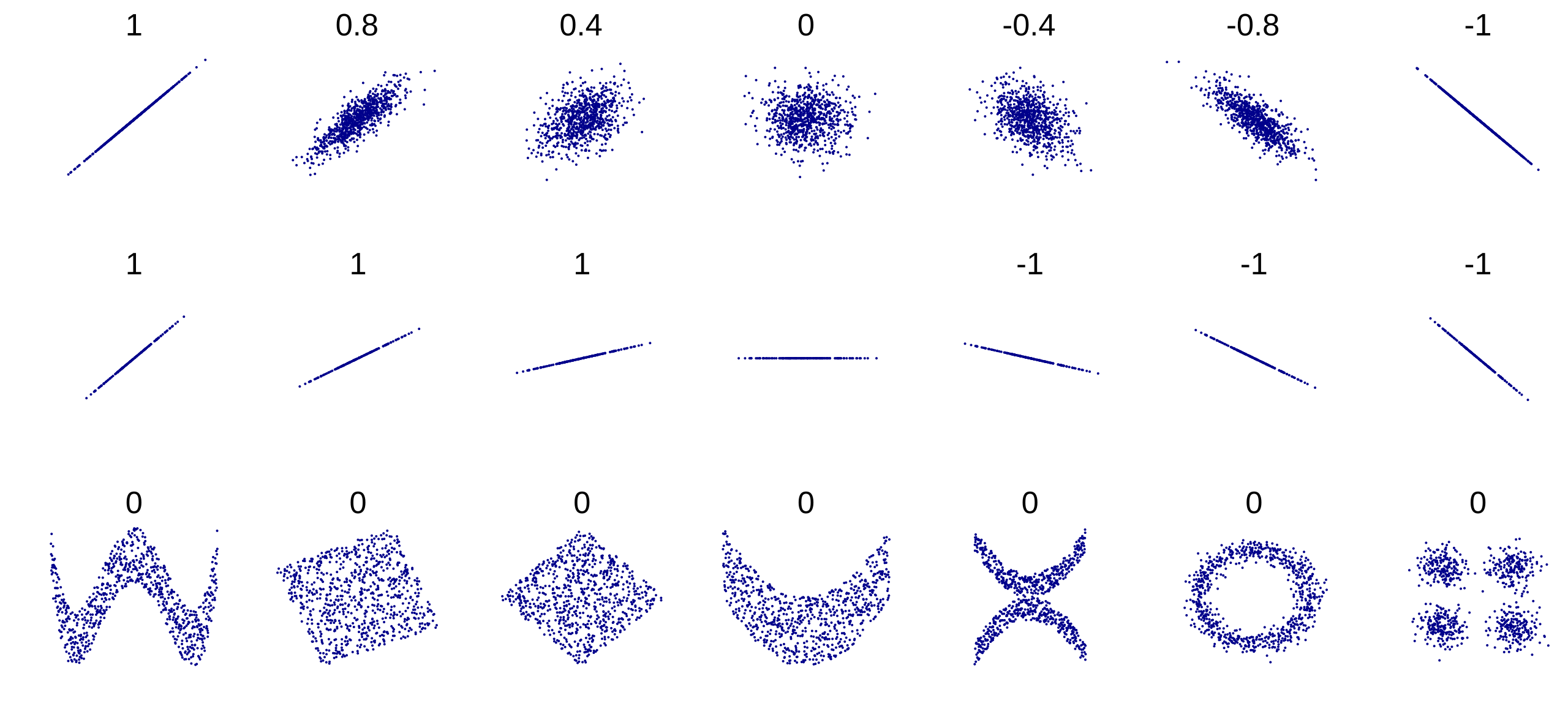
When it comes to the last row – this happens more frequently in reality than in text books or computer models – conventional correlations will miss significant interdependencies, impacting the reliability of a model and providing wrong answers. And what about the cases illustrated below (known as Anscombe’s quartet)? The four datasets have nearly identical simple descriptive statistics, but have very different distributions.

QCM/Artificial Intuition is able to distinguish between these four cases and attribute correct “correlation” values to each case. This is because a radically new, proprietary approach to correlation has been developed – known as generalized correlation – which has got nothing to do with regressions, means and standard deviations, probability distributions or linearity/non-linearity.
Finally, when it comes to ranking the criticality of variables, no use is made of PCA or ANOVA.
In the case of Artificial Intelligence the differences with QCM/Artificial Intuition are even more evident.
Artificial Intelligence/Machine Learning requires a training set. This inevitably introduces bias. Different training sets will ultimately lead to different outcomes.
In numerous real-life cases, there exist extremely rare, yet costly anomalies for which it is impossible to produce a significantly rich training set precisely because they are rare. Therefore, no training is possible.
In numerous real-life cases, high complexity often means that the number of possible anomalies is astronomical. Clearly, training for unknown anomalies is impossible.
When the context changes – for example when new factors come into play, new equipment is installed, new variables are added or removed, etc., – training must be repeated.

Super, simple and powerful as usual. For intentional decision makers who seek actionable knowledge amidst deep uncertainty and complexity; and not for time wasters.
Samuel.
LikeLike