
The success of AI hinges on the quality and diversity of its training data. AI models learn from a vast array of information, which can be broadly categorized into static and dynamic. Static data is often text, symbols, or images. Dynamic data may be sounds, vidoes, or time-depedent data, like an accelerogram during an earthquake.
In this blog we introduce Complexity Spectra as a new type of data which may be used for AI training. It targets specifically time-dependent data, like that available in an Operating Room, an Intensive Care Unit, a factory floor, or data streaming from a piece of equipment, or a car, or even the motions of atoms in a chemical compound. These sources can produce very large amounts of data, meaning training can be slow and expensive.
Complexity Spectra not only condense large quantities of data by orders of magnitude, they also contain additional information which raw data does not. They are obtained by processing raw data with our QCT engine OntoNet™ and have the form of a bar chart. The magnitude of each entry is not only proportional to the “importance” of each variable in the entire data set, it also measures the information encoded by a given variable (data channel) in relation to all the other variables. It therefore carries tremendous systemic-type of information.
At this point, we have two possible AI training strategies: directly with raw data and, in alternative, based on Complexity Spectra, as shown in the scheme below.
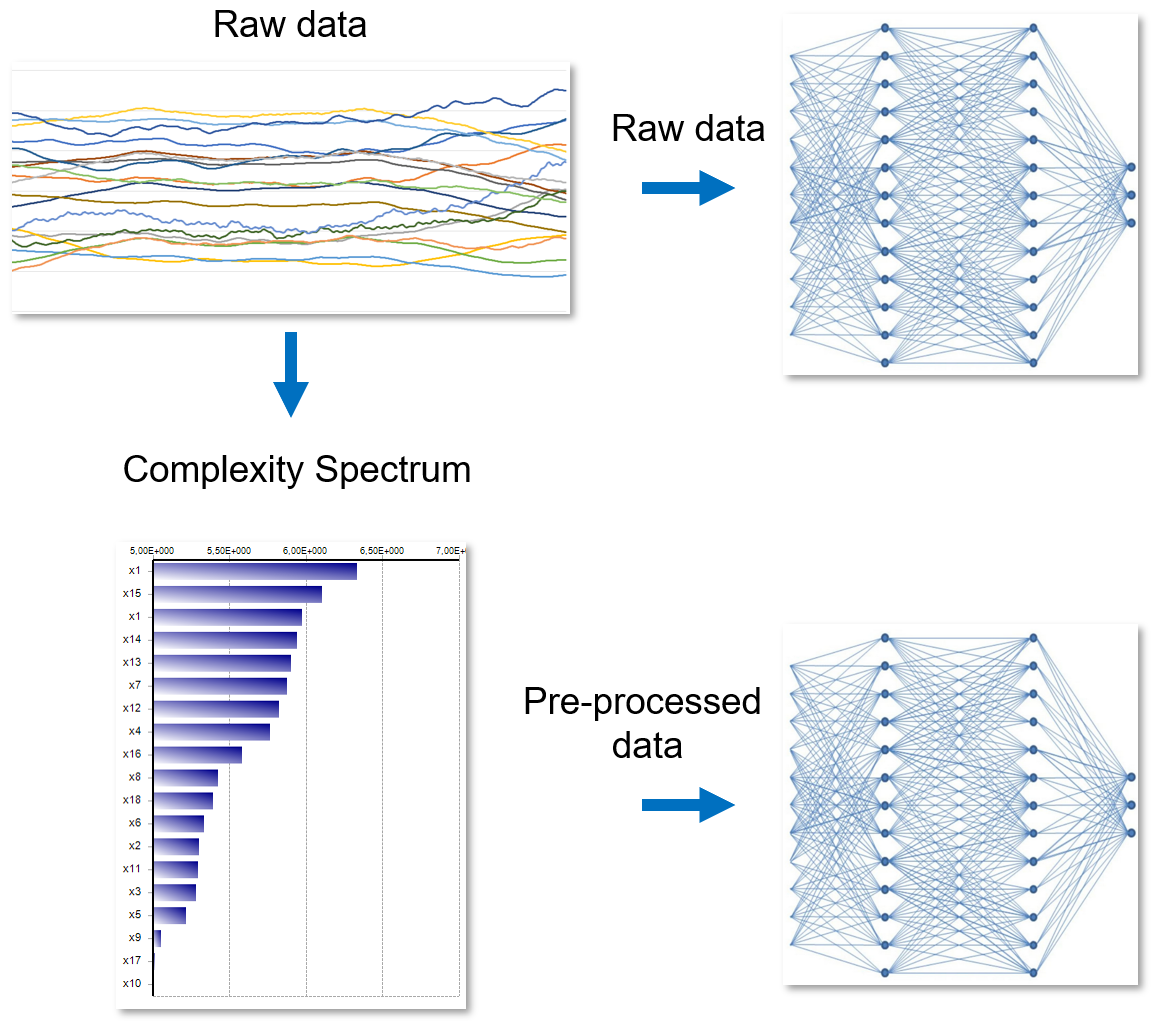
Not only does this pre-process reduce massively the size of data, by mapping time-dependent data onto a single vector, it can also reduce enormously the workload in the training itself. This is because a Complexity Spectrum already contains information about the relative footprint of the variables, instead of having the Neural Net figure it out for itself.
Let’s suppose that for each input data set there will be a corresponding output. At the end of the day, training data may have the following forms, where i varies from 1 to N and represents the i-th input-output pair:
Input: [x(t)]_i, Output: [corresponding output]_i
Input: [Complexity Spectrum]_i, Output: [corresponding output]_i
The number of neurons on the input layer obviously remains the same.

0 comments on “A New Class of AI Training Data”