

Wikipedia: “In data mining, anomaly detection (also outlier detection) is the identification of rare items, events or observations which raise suspicions by differing significantly from the majority of the data. Typically the anomalous items will translate to some kind of problem such as bank fraud, a structural defect, medical problems or errors in a text. Anomalies are also referred to as outliers, novelties, noise, deviations and exceptions.
In particular, in the context of abuse and network intrusion detection, the interesting objects are often not rare objects, but unexpected bursts in activity. This pattern does not adhere to the common statistical definition of an outlier as a rare object, and many outlier detection methods (in particular unsupervised methods) will fail on such data, unless it has been aggregated appropriately. Instead, a cluster analysis algorithm may be able to detect the micro clusters formed by these patterns.”
Machine learning may be used to detect anomalies very efficiently. This is accomplished by presenting the learning algorithm with tens, hundreds or even thousands of examples of anomalies. Nothing new under the Sun.
All systems function and transition between modes, i.e. different configurations, or states.The oscillation can be spontaneous – think of how the climate transitions between the four seasons – or deliberate. An example is that of an aircraft that switches from a “climb mode” to a “cruise mode”, or a person that runs, sleeps or eats. In a given mode of functioning, information flows within the system in question in a particular manner, according to certain patterns which changes when the mode is changed. In most cases we know what these modes are.
We know that modal analysis is equivalent to finding a set of ‘shape functions’, which combined appropriately can describe a complex shape. An example of two modes of a clamped-free and simply supported beam are illustrated below.
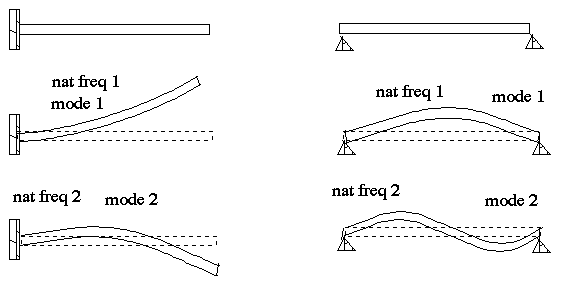
Modal analysis is very common in structural engineering. It helps understand the dynamics of vibrating structures as well as resonance frequencies which, in general, are to be avoided. Typically, the dynamics of vibrating structures – bridges, building, aircraft, solar arrays on a satellite – can be described with a small number of fundamental modes.
When highly complex systems are concerned, such as IT or telecommunication networks, electronics in an aircraft or a car, or critical infrastructures, things assume a very different connotation. This is because large high-dimensional systems can exhibit a fantastically huge number of modes of functioning, many of which can be non-intuitive or simply unknown. Super complex systems are generally highly nonlinear and running a conventional modal analysis is simply impossible. However, a procedure similar to modal analysis can still be performed thanks to QCM (Quantitative Complexity Management) techniques.
A complexity analysis of generic systems is performed by analyzing the structure of information flow between the various channels in that system. Below is a simple example of a system that is described by 10 variables (channels), and which is monitored over a period of time. A total of 4000 samples are collected (in other words, the corresponding data matrix is 4000 x 10). When we run this data through OntoNet – our complexity analysis and management engine – we discover that this system can function in 88 separate modes. A few of these modes are illustrated below. Each mode reflects the ‘instantaneous correlation structure’ of the system in question.

For example, our small system can function for a certain amount of time (within the 10-dimensional space spanned by the 800×10 data) in mode 88. What this means that there is a position, within the 800×10 data universe, in which the only active correlation is that between channel 1 and channel 3, all remaining correlations being chaotic. Mode 5, on the other hand, shows a more complex situation, in which the information flow has a much richer topology. The bottom line is that the 88 modes can be used (superimposed) to describe any situation in which the system may find itself functioning. Now, this tiny 10-dimensional system can function in up to 88 modes. Think what the number of modes can be in a space with 1000 or 100000 dimensions.
This brings us back to the original issue of anomaly detection. First of all, there are many contexts in which an anomaly may be fatal. Many of our clients don’t have the luxury of being able to survive hundreds of anomalies only to be able to train a system to recognize the next one. Conventional anomaly detection utilizes machine learning to teach a system to recognize anomalous situations. However, as we have seen, in highly complex systems there exists thousands of possible modes of functioning and for each mode there may be as many potential anomalies. As complexity increases, these numbers increase too. Think of the global financial system in which more than 70% of trades is run by robots that form a super-huge ecosystem in which they compete. Imagine the system of systems that critical infrastructures form, or the Internet of Things. How many points (or modes) of failure do these systems have? Nobody knows. What makes these systems powerful, also makes them fragile. Complexity is a next generation risk which requires a next generation technology and approach. So, how do you detect an anomaly in such contexts? What is an anomaly in such circumstances? Clearly, the classical approach won’t work.
QCM suggests a different solution. We know that rapid complexity fluctuations (spikes) anticipate (or accompany) phase changes or mode transitions in dynamical systems (problems, in plain English). In many cases they provide a formidable early warning signal. An example is shown below.

However, the early warning feature that rapidly changing complexity possesses is only the icing on the cake. In many cases it is already immensely important to simply know that something harmful or damaging is taking place. To be able to answer the question “are we under attack?” or “is our system becoming fragile?” is already a feat in many cases. So, what is the new paradigm?
1. Monitor constantly the complexity of your system (or business) and watch out for sudden variations in complexity.
2. When a complexity spike appears, examine the Complexity Profile (which OntoNet creates at each analysis step) to find out which variables in the system are responsible for the spike. These are to be found at the top of the list. An example is shown below. A Complexity Profile is simply a bar chart which ranks all data channels based on their contribution to total system complexity. When this increases suddenly it is always a good idea to know why and who is responsible.

A special purpose device for monitoring complexity of critical components has been built by Ontonix and SAIC. The device is illustrated below. It can be hooked up to the data BUS on a car, and aircraft, a submarine, a transformer in an electrical grid, and can monitor in real-time the corresponding complexity, issuing alarms in case of sudden variations. The idea is to identify the onset of catastrophic systemic collapses

Basically, what this means is that we no longer need to define or model or catalog anomalies. By the way, once we’re done doing that the anomalies have changed. A sudden spike in complexity is an anomaly and we don’t need to train OntoNet to recognize it. It just does. With the QCM we can get it right the first and only time a particular problem appears.

0 comments on “Complexity and Revisiting Anomaly Detection”