

Anomaly detection, especially their early detection, is a crucial capability when it comes to operating large complex systems, processes or critical infrastructures. Because it is difficult to make highly complex systems resilient in the face of a multitude of potential often unknown hazards, it is desirable to be able to identify anomalies, malfunctions and attacks prior to their materialization. This is possible, but not all the time.
All systems can be decomposed into four sub-systems:
- controllable and observable – it is possible to change the sub-system’s state and to observe the effect.
- controllable but not observable – it is possible to act upon a sub-system but not to measure (directly) the outcome
- observable but not controllable – one may observe the outputs produced by a sub-system but one has no means of influencing it
- not controllable, not observable – this is the case of a sub-system that has no actuators attached to it and no sensors that would allow to see what it does
This is illustrated below by means of a simple four-mode system.
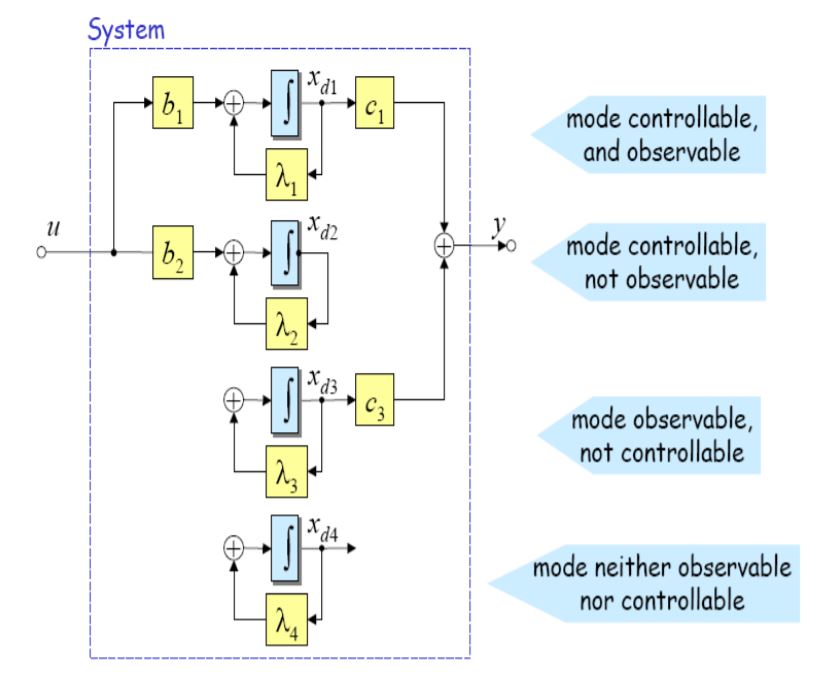
These four subsystems are not always present. However, in highly complex systems, such as very large software systems, weapon systems, networks, or critical infrastructures, involving millions of variables, one can be sure that all of them exist.
In the most general case, the four subsystems may communicate without the user knowing it. And this is the cause of plenty of trouble. This effect is called spillover and there are two types: control and observation spillover. Spillover can be very dangerous because it can be difficult to spot.
In order to control a system one needs sensors, actuators and a control logic as illustrated below.
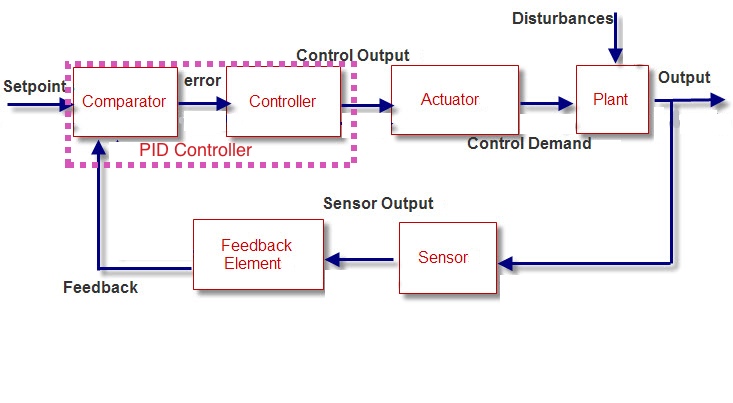
Depending on where actuators and sensors are placed, it may be more or less difficult to control a given system. If, for example, an actuator is placed in a location where it is inefficient, i.e. close to a constraint, it will require much more energy to implement a given control strategy. The same is true of sensors and of their placement. Sensors are of course the most important piece of hardware when it comes to anomaly detection as they provide an instantaneous image of the system under consideration.
In highly complex systems, the efficient placement of actuators and sensors is not easy.
Anomalies or malfunctions may be classified in different ways:
- due to external (exogenous) causes
- due to internal (endogenous) causes
The first type offers no early warning. Type two is a different story as they usually take time to manifest themselves and embrace various subsystems in a process of contagion. These anomalies, for which sensors don’t exist, are the ones that most often cause an increase in complexity which is easy to spot.
Anomalies may be:
- intermittent
- permanent
Intermittent short duration anomalies are difficult to spot and determining their cause increases as the complexity of a system increases. They may also offer little or no early warning.
There is also another classification:
- directly observable – a specific sensor exists, e.g. tyre pressure sensor in a car
- indirectly observable – for example fever, which may indicate an infection (but there are no ‘infection sensors’) or other related symptoms
The second class of anomalies is most insidious. It may often take hours or days even to realize that something has gone wrong. One of the laws of systemantics even states that highly complex systems operate in failure mode. And nobody knows. So, just knowing that something is wrong is often a luxury. In such cases, wanting an early warning is an infantile fantasy.
However, the true problem lies in the fact that:
In highly complex systems the number of potential anomalies can be astronomical.
It is impossible to learn to recognize them all. Besides, systems evolve over time, which means that it may be necessary to continue re-learning old lessons to keep up with the constant changes. This can be very costly, not to say impractical. And quite difficult if someone is, say, firing missiles at you.
Our QCM technology offers a radically innovative alternative to conventional anomaly detection based on Machine Learning. We know (from experience) that when ‘strange things’ happen in complex systems (but not only in complex systems) it is because under the surface a phase change or a mode switching is taking place. Such phenomena manifest themselves in sudden variations in the complexity function as well as in numerous other complexity-related indicators which we have developed recently, such as the Cn1 and Cn3. An example of what this looks like is shown below, where the German DAX30 index is shown as it plummets at the end of February 2020. The Cn3 function, illustrated below, peaks suddenly, approximately 40-50 hours before the index falls.

The important thing is this: there is no learning here, no prior knowledge of stock market dynamics, just one data channel: the DAX 30 index, sampled at one hour intervals.
But this was easy. It was an evident systemic failure. The really nasty cases are those in which there is a problem with a system but one cannot put a finger on it – one feels something is not right but cannot even imagine where to start to look for a malfunction or rupture. Pinpointing similar problems can take a very long time and this means huge costs. QCM comes to the rescue because it offers various indicators that are particularly responsive in the case of nasty but systemic issues.
Last but not least one must not forget the Principle of Incompatibility. This principle, coined by the late L. Zadeh, states that:
High complexity is incompatible with high precision
People – and this includes engineers – often forget that as a system becomes more complex and intricate, it becomes increasingly difficult to make precise statements about it. What this means is that a ‘small’ anomaly may be difficult to identify precisely because complexity will drown it and make the search tedious. In other words, the resolution of an instrument must be in proportion to the complexity of the problem at hand. One obviously doesn’t use a hammer to fix a watch movement or an electron microscope to study a tornado.

0 comments on “On Anomaly Types and Anomaly Detection.”