

Stefano Zampini, CINECA SCAI department, Via dei Tizii 7-8, 00161 Rome, Italy
Claudio Arlandini, CINECA SCAI department, Via Sanzio 4, 20090 Segrate, Italy
Abstract
This paper describes the work done on the Ontonix complexity measurement software. The main activities of the project concerned producing a parallel version of the processing algorithm (based on the Singular Value Decomposition (SVD) method) and testing its applicability to large problems.
1. Introduction
The Ontonix Software Suite consists of a series of modules: first of all OntoNet, a engine capable of measuring the complexity and other metrics such as robustness, resilience of a generic system, where the system is described by N numerical variables. In addition, the Ontonix Software Suite includes other modules with functionalities aimed to support the analysis of the above metrics. The input data processed by OntoNet consist of X tables of data with N columns (variables) and M rows (observations, for examples historical series). The computing resources needed by OntoNet are very sensitive to the X, N and M numbers and when they become large figures the traditional computers available in the marketplace are not capable to provide the needed computing power. The aim of the project is to adapt the Ontonix Software to a parallel computing environment and allow the possibility to compute the complexity for very large dataset, enabling the possibility to tackle the problem of complexity of world scale environments/domains, like the complexity of the system made of all enterprises quoted in all stock exchanges around the world.
While some parts of the software are patented, like the pre-processing of input data for the preparation of the input matrix, the core part of the processing algorithm is based on Singular Value Decomposition (SVD) and therefore open-source. Since the SVD method is common to other application contexts, the enabling work and the experience are relevant to other users and communities.
The Ontonix core module requires the computation of the whole eigenvalue spectrum of real large symmetric dense matrices; eigenvectors computation is not needed. Many well-known algorithms exist in literature to solve the problem, and they can be primarily classified as direct or iterative methods. Direct methods perform the task by first reducing the original matrix to tridiagonal form and then computing the eigenvalues of the resulting tridiagonal matrix. On the other hand, iterative methods progressively compute the eigenvalue spectrum by means of matrix-vector multiplications and Gram-Schmidt orthogonalizations and are mainly designed for problems where the matrix is sparse and the number of required eigenvectors is modest; therefore, direct methods should be preferred for the case of interest. Moreover, it thus becomes clear that the total available RAM and the total RAM per core are the computational bottlenecks of the problem. In the spirit of don’t reinventing the wheel, the development of an ad-hoc code from scratch to perform the task should be avoided since it can be very time consuming and prone to numerical stability issues.
Within direct methods, two different approaches can be taken into account: a distributed memory approach or an out-of-core
computation. At present, the only software which is able to perform an out-of-core computation of the eigenvalue spectrum is FLAME [1], but it does not support a distributed memory computation. Instead, many well-known libraries for distributed memory High Performance Linear Algebra exists; among others, there are PLAPACK [2], ScaLAPACK [3] and the most recent Elemental [4]. PLAPACK is no longer maintained and thus it will not take into account. ScaLAPACK and Elemental have been compared in a recent article [5] using the computational times as a metric; in all of the cases considered, Elemental was found to be as fast as the fastest ScaLAPACK routine, either for the reduction to tridiagonal form, or for the solution of the tridiagonal eigenvalue problem. In particular, Elemental outperformed ScaLAPACK regarding parallel efficiency on the BlueGene/P machine Jugene.
2. Early experimental results
In this Section we report on experimental results obtained on the BlueGene/Q machine FERMI (10’240 power A2 sixteen-core nodes running at 1.6 Ghz and equipped with 16 GB of RAM). Elemental has been compiled using XL compilers, with optimization level -O3 in a pure MPI mode without pthread or openmp support, using the ESSL library as BLAS implementation and a full LAPACK implementation (i.e. not the one provided by the ESSL library). Elemental is written in C++ and can support single or double precision computations; instead, the core of the tridiagonal eigensolver is written in C and explicitly coded for double precision values. Therefore, the following results will be given for double precision computations only.
Elemental uses an element-wise block-cyclic distribution of matrices; this means that a square matrix of size n distributed across a pxq grid of MPI processes needs at least 8n2/(pq) bytes of memory per MPI process to store the local values of the distributed matrix. Since the matrices of interest are symmetric, only the upper triangular part is stored; however, the lower triangular part is still allocated since it is needed by the algorithm itself when performing the reduction to tridiagonal form, overwriting the matrix values.
A simple C++ program, referred to in the following as driver, has been written to test Elemental. The driver first creates a parallel symmetric dense matrix with a clustered spectrum of eigenvalues and then runs the Elemental core functions for the computation of the eigenvalues. Whenever possible, the driver exploit the algorithmic features of the eigenvalue routines of Elemental by considering a square grid of MPI processes. For sake of completeness, eigenvectors computation is not performed.
Since the computational bottleneck of the problem of interest is the available memory, we first run a test case to find the greatest allowed dimension of the local matrices. In details, the driver has been run with a 4×4 grid of MPI processes restricting the computation on a single FERMI node. Computational timing results are shown in Fig 1 as a function of the matrix size. The greatest matrix size allowed resulted to be 40’000, which means that the greatest allowed size for the local matrices is 10’000 (i.e. 750 MB in double precision).
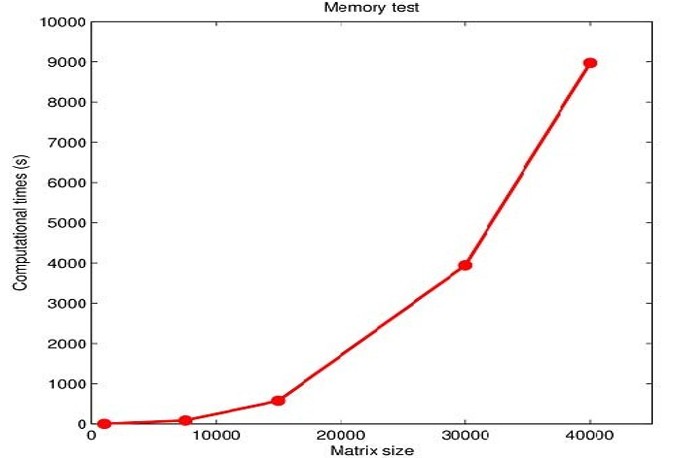
Fig. 1. Computational times for Elemental driver as a function of matrix size within a FERMI node.
A weak scalability test has then been performed to investigate the parallel efficiency of the algorithm implemented by Elemental; in details, the local problem size is kept fixed (10’000) and the parallel driver has been run with a different number of MPI processes, ranging from 16 to 1’024; thus, the matrix size grows until 320’000 using 1’024 MPI processes. Computational times (in hours) are shown in the left panel of Fig. 2; the right panel contains the parallel efficiency of the algorithm.

Fig. 2: Weak scalability test: Computational times (left) and parallel efficiency (right) of Elemental eigensolver.
Finally, Table 1 contains an extrapolation up to 65’536 MPI processes obtained by fitting the computational times collected from the weak scalability test with a second-order polynomial in the number of MPI processes; the resulting matrix sizes are also provided.
| MPI processes | Matrix size | Computational times (hours) |
| 4’096 | 640’000 | 41 |
| 16’384 | 1’280’000 | 82 |
| 32’768 | 2’560’000 | 164 |
Table 1 Extrapolation of computational times for the weak scalability test.
3. Conclusions
In this work we have investigated the possibility of solving the real symmetric dense eigenvalue problem required by the Ontonix project using a distributed memory approach on the BlueGene/Q machine FERMI. The state-of-the-art High Performance library for Dense Linear Algebra Elemental has been used to fulfill the task. Preliminary results suggest that the problem will be solvable in a reasonable amount of time (5 days) using roughly one fourth of the BlueGene/Q machine if the matrix size is below 2’560’000. Otherwise, other techniques should be investigated if both of the following requirements can be fulfilled: a) not all the eigenvalue spectrum is required and b) the matrix can be sparsified. In such a case, iterative methods can be successfully used together with an out-of-core implementation of the matrix-vector product.
Acknowledgements
This work was financially supported by the PRACE project funded in part by the EUs 7th Framework Programme (FP7/2007- 2013) under grant agreement no. RI-283493. The work is achieved using the PRACE Research Infrastructure resource FERMI, located at CINECA, Italy.
References
- FLAME home page: http://z.cs.utexas.edu/wiki/flame.wiki/FrontPage
- PLAPACK home page: http://www.cs.utexas.edu/~plapack
- ScaLAPACK home page: http://www.netlib.org/scalapack
- ELEMENTAL home page: https://code.google.com/p/elemental
- M. Petschow, E. Peise and P. Bientinesi, High-Performance Solvers for Dense Hermitian Eigenproblems, available at http://arxiv.org/pdf/1205.2107v2.pdf

Ontonix Software to Fly Onboard Alsat#1 Cubesat
This is from mid 2020.
Mike
LikeLike
Reblogged this on muunyayo .
LikeLike