

Models are simplified representations or emulators of reality. They are typically based on empirical data collected conducting experiments. There exist numerous techniques for establishing models based on raw field data. An example of a linear model, built based on 2-dimensional data is illustrated below.
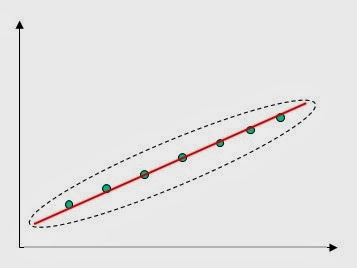
The model in this simple case is a straight line. It may be used, for example, to compute the value of one variable when the other is given. This is particularly useful for values which fall in between the raw data used to build the model.
A more interesting case is illustrated below. Here too the data lie on a straight line. However, there is a void between the two groups of data points. This poses a problem. In cases such as this one a single model is built, passing through both groups of points. In other words, a most dangerous assumption is made: that of continuity. This is a very common mistake. The mere fact that all the points in question lie on a straight line does not guarantee that in the void between the two groups the line still constitutes a valid model.
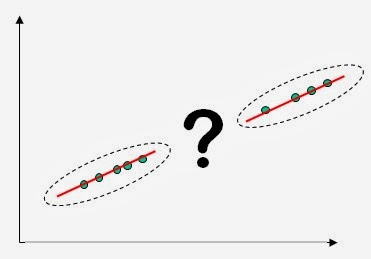
The mistake proves often fatal, and more so when the domain one wishes a particular model to embrace is more articulated. In the above case, there should be two local models, not one.
Models should be used with caution and ONLY in the domains where they have been validated. Extending the usage of a model beyond such a domain has consequences which grow with the model’s complexity. Moreover, when a model’s applicability is stretched, very seldom the effects are actually measured. The actual equations might still work but that does not guarantee that the model isn’t violating some basic laws or rules.
The bottom line:
- Models should be used only in the domain where they have been validated.
- More complex models require more assumptions and therefore induce more uncertainty into the original problem than simpler models.
- The more complex a domain (in topological sense) that a model has to embrace, the easier it is to violate some basic laws with it. And it is more difficult to spot them.
- The most frequent and deadly malpractice when models are involved is the assumption of continuity. Nature is not “smooth and differentiable”.
- The additional risk deriving from the fact that a surrogate of reality is used is rarely measured.
One more rule: the most important things in a model are those it doesn’t contain.

0 comments on “Modeling Risk and Model-Induced Risk”